
The below post is notes prepared by me by studying the book "Database Systems Design, Implementation and Management" by Peter Rob and Carlos Coronel
Content, examples and diagrams are taken from that book.
Q: What is an information system?
Ans: A complete information system is composed of people, hardware, software, the databases, application programs and procedures.
The process of creating an information system is known as system development.
Q: The system development life cycle(SDLC)
The SDLC is an iterative rather than a sequential process.
1. Planning:
The SDLC planning phase yields a general overview of the company and its objectives.
An initial assessment of the information flow-and-extent requirements must be made to answer questions like
Should the existing system be continued?
Should the existing system be modified?
Should the existing system be replaced?
If it is decided that a new system is necessary, then it is checked whether the new system is feasible or not. The feasibility study includes
- Technical feasibility: Can the development of the new system be done with current equipment, existing software technology, and available personnel? Does it require new technology?
- Economic feasibility: Can we afford it? Is it a million dollar solution for a thousand dollar problem?
- Operational feasibility: Does the company possess the human, technical and financial resources to keep the system operational? Will there be resistance from users?
2.Analysis:
A thorough audit of user requirements and
understanding of system’s functional areas, actual and potential problems and opportunities.
The logical design must specify the appropriate conceptual data model, inputs, processes and expected output requirements using tools such as DFDs,ER diagrams etc..
All data transformations (processes) are described and documented using such system analysis tools.
3.Detailed System design
The design includes all the necessary technical specifications for the screens, menus, reports and other devices that might be used to help make the system more efficient information generator.
4. Implementation
The hardware, DBMS software and application programs are installed and the database design is implemented.
During the intial stages of implementation phase, the system enters into a cycle of coding, testing and debugging until it is ready to be delivered.
The system will be in full operation by the end of this phase but will be continuously evaluated and fine-tuned.
5. Maintenance
Maintenance includes all the activity after the installation of software that is performed to keep the system operational.
Major forms of maintenance activities are
fixing of errors fall under corrective maintenance.
Adaptive maintenance due to changes in the business environment.
Perfective maintenance to enhance the system.
UNIT-IV Chapter-I
Transaction management and concurrency control
What is a transaction?
A transaction is any action that reads from and / or writes to a database.
A transaction is a single, indivisible, logical unit of work.
All transaction are controlled and executed by the DBMS to guarantee database integrity.
Q: Transaction properties or ACID test
Each individual transaction must display Atomicity, Consistency, Isolation and Durability.
Atomicity: requires all operations (SQL requests) of a transaction be completed if not the transaction is aborted.
If a transaction T1 has four SQL requests, all four requests must be successfully completed otherwise the entire transaction is aborted.
Consistency: A transaction takes a database from one consistent state to another.
Isolation: means that the data used during the execution of a transaction cannot be used by a second transaction until the first one is completed.
If transaction T1 is being executed and is using data item X, that data item cannot be accessed by any other transction until T1 ends.
Durability:ensures that once transaction changes are done(committed), they cannot be undone or lost, even in the event of a system failure. COMMITED TRANSACTIONS ARE NOT ROLLED BACK
When executing multiple transactions the DBMS must schedule the concurrent execution of the transaction’s operations. The schedule of such transaction’s operations must exhibit the property of serializability.
Serializability ensures that the schedule for the concurrent execution of the transactions yields consistent results.
Q: Transaction management with SQL
Transaction support is provided by two SQL statements : COMMIT and ROLLBACK.
Transaction sequence must continue through all succeeding SQL statements until one of the following four events occurs.
- A COMMIT statement is reached, in which case all changes are permanently recorded within the database.
The COMMIT statement automatically ends the SQL transaction.
Ex: UPDATE product SET qoh = qoh-2 WHERE pno=’P01’;
UPDATE customer SET baldue = baldue+20 where cno = 201;
COMMIT;
- A ROLLBACK is reached, in which case all changes are aborted and the database is rolled back to its previous consistent state.
- The end of a program is successfully reached, in which case all changes are permanently recorded within the database. This action is equivalent to COMMIT
- A program is abnormally terminated, in which case changes made in the database are aborted and the database is rolled back to its previous consistent state. This action is equivalent to ROLLBACK.
A transaction begins implicitly when the first SQL statement is encountered.
SQL SERVER uses transaction management statement such as BEGIN TRANSACTION; to indicate beginning of a new transaction.
The Oracle RDBMS uses the SET TRANSACTION statement to declare a new transaction start and its properties.
Q: The Transaction Log:
A DBMS uses a transactional log to keep track of all transactions that update the database.
The information stored in this log is used by the DBMS for a recovery requirement
The transaction log stores:
- A record for the beginning of the transaction.
- For each transaction component (SQL statement ):
The type of operation being performed (update, insert, delete)
The names of the objects affected by the transaction ( the name of the table)
The before and after values for the fields being updated.
Pointer to the previous and next transaction log entries for the same transaction.
- The ending (COMMIT) of the transaction.
A transaction log
TRL_ID
|
TRX_NUM
|
Prev PTR
|
Next PTR
|
Operation
|
Table
|
RowID
|
Attribute
|
Before Value
|
After Value
|
341
|
101
|
Null
|
352
|
START
|
**Start Transaction
| ||||
352
|
101
|
341
|
363
|
UPDATE
|
PRODUCT
|
P01
|
qoh
|
20
|
18
|
363
|
101
|
352
|
365
|
UPDATE
|
CUSTOMER
|
201
|
baldue
|
100
|
120
|
365
|
101
|
363
|
Null
|
COMMIT
|
**End of Transaction
|
Concurrency Control
The Coordination of the simultaneous execution of transactions in a multi user database system is known as concurrency control.
Problems due to concurrent transaction due to lack of concurrency control are:
- Lost updates
- Uncommited data and
- Inconsistent retrievals
Lost updates occurs when two concurrent transactions, T1 and T2 are updating the same data element and one of the upadates is lost (overwritten by the other transaction)
Ex: consider two concurrent transactions to update qoh
Transaction
|
Computation
|
T1 :Purchase of 100 units
|
qoh = qoh + 100
|
T2: Sell 30 units
|
Qoh = qoh - 30
|
Serial execution of above transactions
Time
|
Transaction
|
Step
|
Value
|
1
|
T1
|
Read qoh
|
35
|
2
|
T1
|
qoh = 35+ 100
| |
3
|
T1
|
Write qoh
|
135
|
4
|
T2
|
Read qoh
|
135
|
5
|
T2
|
qoh = 135-30
| |
6
|
T2
|
Write qoh
|
105
|
The below table shows how a Lost Updates problem can arise
Time
|
Transaction
|
Step
|
Value
|
1
|
T1
|
Read qoh
|
35
|
2
|
T2
|
Read qoh
|
35
|
3
|
T1
|
qoh = 35+ 100
| |
4
|
T2
|
qoh = 35-30
| |
5
|
T1
|
Write qoh (lost update)
|
135
|
6
|
T2
|
Write qoh
|
5
|
Uncommited data or dirty read occurs when two transactions T1 and T2 are executed concurrently and the first transaction (T1) is rolled back after the first transaction (T1) is rolled back after the second transaction (T2) has already accessed the uncommitted data - thus violating the isolation property of transactions.
Time
|
Transaction
|
Step
|
Value
|
1
|
T1
|
Read qoh
|
35
|
2
|
T1
|
qoh = 35+ 100
| |
3
|
T1
|
Write qoh
|
135
|
4
|
T1
|
***ROLL BACK**
|
35
|
5
|
T2
|
Read qoh
|
35
|
6
|
T2
|
qoh = 135-30
| |
7
|
T2
|
Write qoh
|
5
|
Time
|
Transaction
|
Step
|
Value
|
1
|
T1
|
Read qoh
|
35
|
2
|
T1
|
qoh = 35+ 100
| |
3
|
T1
|
Write qoh
|
135
|
4
|
T2
|
Read qoh
|
135
|
5
|
T2
|
qoh = 135-30
| |
6
|
T1
|
***ROLLBACK***
|
35
|
7
|
T2
|
Write qoh
|
105
|
Inconsistent retrievals occur when a transaction accesses data before and after another transaction finish working with such data.
For ex: T1 calculates summary( aggregate) function over a set of data while another transaction T2 is updating same data
Transaction T1
|
Transaction T2
|
SELECT SUM(qoh) FROM product WHERE pno < ‘P04’;
|
UPDATE product SET qoh = qoh + 10 WHERE pno = ‘P01’;
|
Time
|
Transaction
|
Action
|
Value
|
Total
|
1
|
T1
|
Read qoh for pno = ‘P01’
|
10
|
10
|
2
|
T2
|
Read qoh for pno = ‘P01’
|
10
| |
3
|
T2
|
qoh = 10 + 10
| ||
4
|
T2
|
Write qoh for pno = ‘P01’
|
20
| |
4
|
T1
|
Read qoh for pno = ‘P02’
|
3
|
13
|
5
|
T2
|
***COMMIT***
| ||
6
|
T2
|
Read qoh for pno = ‘P03’
|
5000
|
5013
|
The computed answer of 5013 is wrong as the correct answer is 5023
Unless the DBMS exercises concurrency control, a multi user database environment can create havoc within the information system.
The Scheduler
If two transactions access unrelated data then
There will be no conflict
And order of execution is irrelevant.
If the transactions operate on related data then
Conflict possible and
The selection of one execution order over another might have undesirable consequences.
The correct order is determined by built - in scheduler.
Q: What is a scheduler?
The scheduler is a special DBMS process that establishes the order in which the operations within concurrent transactions are executed.
The scheduler bases its actions on concurrency control algorithms, such as locking or time stamping methods.
NOT ALL TRANSACTIONS ARE SERIALIZALE
If the transactions are not serializable then the transaction are executed on first-come, first - served basis by the DBMS.
If transactions are executed in serial order one after another then
CPU time will be wasted and
Yields unacceptable response times within the multi user DBMS environment.
Q: What is Serializable Schedule?
Ans: A serializable schedule is a schedule of transaction’s operations in which the interleaved execution of the transactions (T1, T2, T3 etc.) yields the same result as if the transaction were executed in serial order (one after another).
Transaction
| |||
Operations
|
T1
|
T2
|
Result
|
Read
|
Read
|
No Conflict
| |
Read
|
Write
|
Conflict
| |
Write
|
Read
|
Conflict
| |
Write
|
Write
|
Conflict
|
Q: What are conflicting database operations?
Ans: Scheduler facilitates data isolation to ensure two transactions do not update the same data element at the same time.
Two operations are in conflict when they access the same data and atleast one of them is a WRITE operation.
The figure shows Conflicting database operations
Concurrency control with locking methods
A lock guarantees exclusive use of a data item to a current transaction.
A transaction acquires lock prior to data access; the lock is released when the transaction is completed so that another transaction can lock the data item for its exclusive use.
The database might be in a temporary inconsistent state when several updates are executed. Therefore, locks are required to prevent another transaction from reading inconsistent data.
Most multi user DBMSs automatically initiate and enforce locking procedures.
All lock information is managed by a lock manager.
Q: What is lock granularity? Explain?
Ans: Lock granularity indicates the level of lock use.
Locking can take place at the following levels: database, table, page, row or even field.
Database level
In a database level lock, the entire database is locked.
This level of locking is good for batch processes, but it is unsuitable for multiuser DBMSs.
Table Level
In a table level lock, the entire table is locked.
It is unsuitable for multiuser DBMSs.
Page Level
In page level lock, the DBMS will lock an entire diskpage.
Page is equivalent to disk block. A block is the smallest unit of data transfer between the hard disk and the processor.
Row level
The DBMS allows concurrent transactions to access different rows of the same table.
The row - level locking approach
Improves the availability of data but
Its management requires high overhead because a lock exists for each row.
Modern DBMS automatically escalate a lock from row level to page level lock when the application session requests multiple locks on the same page.
Field Level
The DBMS allows concurrent transactions to access different fields within a row.
Field level locking
Yields the most flexible multi user data access but it is
Rarely implemented in DBMS
LOCK TYPES : DBMS may use different lock types: Binary locks and Shared/Exclusive locks
Binary Locks:
A binary lock has only two states: locked (1) or unlocked (0).
If an object is locked by transaction, no other transaction can use that object.
Shared/Exclusive Locks :A shared lock is issued when a transaction wants to read data from the database.
An exclusive lock is issued when a transaction want to update (write) a data item.
Using Shared/Exclusive Locks concept, a lock can have three states: unlocked, shared (read) and exclusive (write).
Lock-compatibility matrix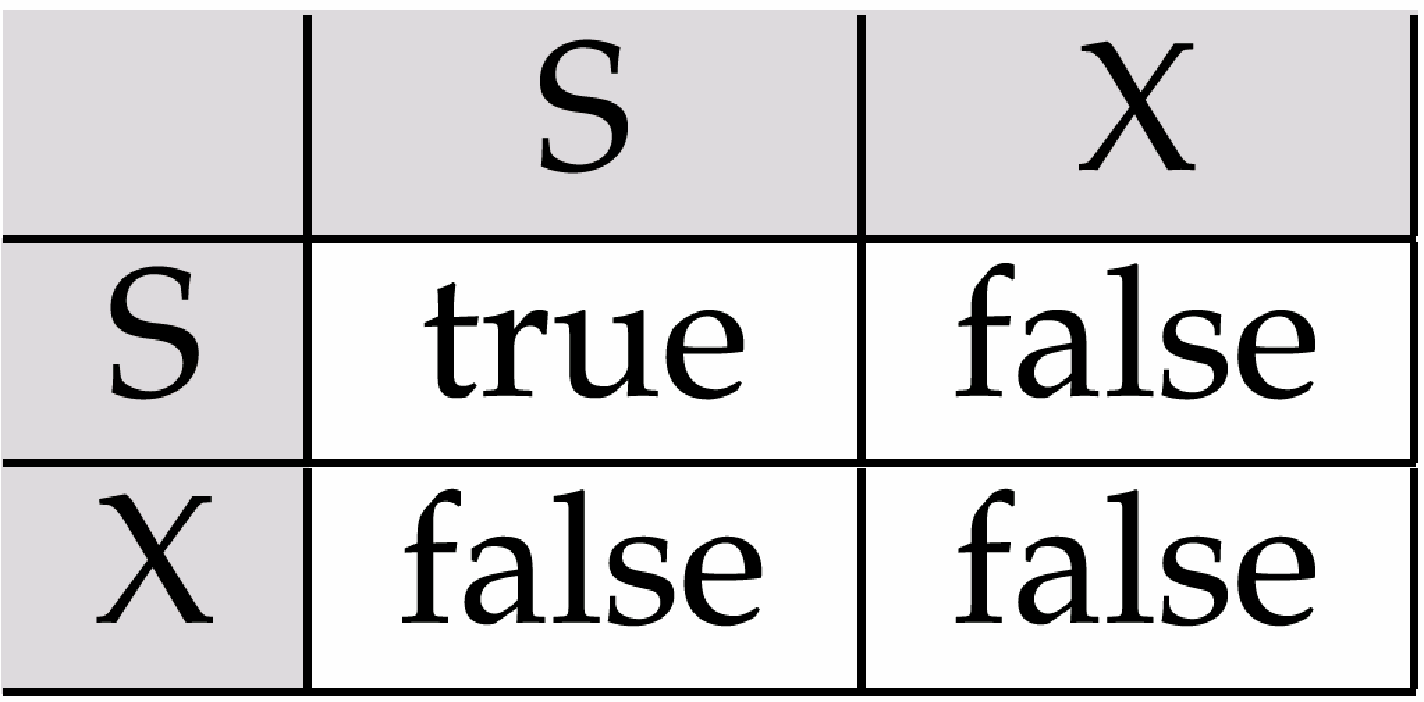
- Any number of transactions can hold shared locks on an item,
but if any transaction holds an exclusive on the item no other transaction may hold any lock on the item.
- If a lock cannot be granted, the requesting transaction is made to wait till all incompatible locks held by other transactions have been released. The lock is then granted.
Although the use of shared locks renders data access more efficiently, a Shared/Exclusive Lock schema increases the lock manager’s overhead for several reasons:
- The type of lock must be known before a lock can be granted
- Three lock operations exist:
READ_LOCK (to check the type of lock)
WRITE_LOCK (to issue the lock) and
UNLOCK (to release the lock)
- The schema has been enhanced to allow a lock upgrade (from shared to exclusive) and a lock downgrade (from exclusive to shared)
Locks prevent serious data inconsistencies but they lead to two major problems:
- Serializability
- Deadlock
Serializability is guaranteed through a locking protocol known as two-phase locking.
TWO-PHASE LOCKING (2PL):defines how transaction acquire and release locks
- ENSURES SERIALIZABILITY
- Does not prevent deadlocks
The two phases are:
Growing Phase:
- Acquires all locks
- Doesnot unlock any data
Once all locks have been acquired, the transaction is in its locked state.
Shrinking Phase:
- Releases all locks
- Cannot obtain any lock
The two phase locking protocol is governed by the following rules
- Two transaction cannot have conflicting locks
- No unlock operation can precede a lock operation in the same transaction
- No data are unaffected until all locks are obtained-- that is until the transaction is in its locked point.
The transaction acquires all of the locks it needs until it reaches its locked point.
When the locked point is reached, the data are modified.
Finally the transaction is completed as it releases all of the locks it acquired in the first phase.
DeadLocks
A deadlock occurs when two transactions wait indefinitely for each other to unlock data.
For example: T1 has locked data item X and waiting for data item Y which is held by T2 and
T2 has locked data item Y and waiting for data item X which is held by T1.
T1 and T2 wait for each other to unlock the required data item. Such a deadlock is also known as deadly embrace.
The figure demonstrates how a deadlock is created.
Time
|
Transaction
|
Reply
|
Lock status
| |
0
|
Data X
|
Data Y
| ||
1
|
T1: LOCK(X)
|
OK
|
Unlocked
|
Unlocked
|
2
|
T2:LOCK(Y)
|
OK
|
Locked
|
Unlocked
|
3
|
T1:LOCK(Y)
|
WAIT
|
Locked
|
Locked
|
4
|
T2:LOCK(X)
|
WAIT
|
Locked
|
Locked
|
3
|
T1:LOCK(Y)
|
WAIT
|
Locked
|
Locked
|
4
|
T2:LOCK(X)
|
WAIT
|
Locked
|
Locked
|
Deadlock
|
The three basic techniques to control deadlocks are:
Deadlock prevention:
A transaction requesting a new lock is aborted when there is the possibility that a deadlock can occur.
If a transaction is aborted, all changes made by this transaction are rolled back and all locks obtained are released.
The transaction is rescheduled for execution.
Deadlock prevention works because it avoids the conditions that lead to deadlocking.
Deadlock detection:
The DBMS periodically tests the database for deadlocks. If a deadlock is found, one of the transaction (“the victim”) is aborted (rolled back and restarted ) and the other transaction continues.
Deadlock avoidance: The transaction must obtain all locks it needs before it can be executed. This technique avoids rollback of conflicting transactions.
The choice of deadlock control method to use depends on the database environment.
For example, if the probability of deadlock is
Low, deadlock detection is recommended.
High, deadlock prevention is recommended.
If the response time is not high on the system’s priority list, deadlock avoidance is employed.
DBMS use a blend of prevention and avoidance for other types of data such as XML data or data warehouses
All current DBMSs support deadlock detection in transactional databases
Concurrency control with time stamping methods
The time stamping approach assigns a global, unique time stamp to each transaction.
Time stamps must have two properties: uniqueness and monotonicity.
Uniqueness ensures that no equal timestamp values can exists
Monotonicity ensures that timestamp values always increase.
All database operations (READ and WRITE) within the same transaction must have the same timestamp.
The DBMS executes conflicting operations in timestamp order.
If two transactions conflict, one is stopped, rolled back, rescheduled and assigned a new timestamp value.
For each data Q two timestamp values have to be maintained. They are
W-timestamp(Q) is the largest timestamp of any transaction that executed write(Q) successfully.
R- timestamp(Q) is the largest timestamp of any transaction that executed read(Q) successfully.
Thus timestamping increases memory needs and database processing overhead and uses a lot of system resources.
WAIT / DIE AND WOUND/WAIT SCHEMES
Assume that you have two conflicting transactions T1 and T2 each with a unique timestamp.
Suppose T1 has a timestamp of 115 and
T2 has a timestamp of 195
That is T1 is older transaction and T2 is newer transaction.
Transaction
Requesting Lock
|
Transaction
Owning lock
|
Wait/ Die Scheme
|
Wound/Wait Scheme
|
T1(115)
|
T2(195)
|
T1 waits until T2 is completed
and T2 releases its lock
|
T1 preempts (rollbacks) T2
T2 is rescheduled using the same timestamp
|
T2(195)
|
T1(115)
|
T2 dies (rollback)
T2 is rescheduled using the same timestamp
|
T2 waits until T1 is completed and T1 releases its lock
|
For A transaction that requests multiple locks.How long does a transaction have to wait for each lock request?
To prevent that type of deadlock, each lock request has an associate timeout value.
If the lock is not granted before the timeout expires, the transaction is rolled back.
Concurrency control with optimistic methods
The optimistic approach is based on the assumption that the majority of the database operations do not conflict.
This has three phases they are:
Read phase: the transaction T reads the data items from the database into its private workspace.
All the updates of the transaction can only change the local copies of the data in a private workspace.
Validate phase:
Checking is performed to confirm the read values have changed during the time transaction was updating the local values. This is performed by comparing the current database values to the values that were read in the private workspace.
Incase the values have changed, the local copies are thrown away and the transaction aborts.
Write phase: The changes are permanently applied to the database.
Database recovery management
Transaction recovery reverses all the changes that the transaction made to the database before the transaction was aborted and to recover the system after some type of critical error has occurred.
Examples of critical events are:
1. Hardware/software failures: Failure of this type could be harddisk media failure, bad capacitor on motherboard, or a failing memory bank, application program or O.S errors that cause the data to be overwritten, deleted or lost.
2. Human- caused incidents are two types: unintentional and intentional
- Unintentional failure caused by carelessness by end users. Such errors include deleting the wrong rows from a table or shutting down the database server by accident.
- Intentional events are security threats caused by hackers and virus attacks.
3. Natural disasters include fires,earthquakes,floods and power failures.
A critical error can render the database in an inconsistent state.
Transaction recovery
Database transaction recovery uses data in transaction log to bring a database to a consistent state after a failure.
Four important concepts that affect the recovery process.
- The write-ahead-log protocol ensures that transaction logs are always written before any database data are actually updated. Recovery is done using the data in transaction log incase of failure.
- Redundant transaction logs ensure that a physical disk failure will not affect the recovery.
- When a transaction updates data, it actually updates the copy of the data in buffer(temporary storage area in primary memory). This process is much faster than accessing the physical disk every time. Later on, all buffers are written to physical disk during a single operation.
- Database checkpoints are operations in which the DBMS writes all of its updated buffers to disk.
While this is happening, the DBMS does not execute any other requests.
Checkpoints are automatically scheduled by the DBMS several times per hour.
Checkpoint operation is also registered in the transaction log.
Q: Write about different types of recovery techniques?
Ans: Transaction recovery procedures generally make use of
Deferred-write also called Deferred Update and
Write-through also called Immediate Update techniques.
In Deferred- write technique, the transaction operations do not immediately update the physical database. Instead, only the transaction log is updated.
The database is physically updated only after the transaction is committed
The recovery process using Deferred-write follows these steps:
- Identify the last checkpoint in the transaction log.
(This is the last time transaction data was physically saved to disk.) - For a transaction that started and committed before the last checkpoint, nothing needs to be done
- For a transaction that performed a commit operation after last checkpoint, the DBMS redoes the transaction using the after values in transaction log.
The changes are made in ascending order from oldest to newest. - For a transaction that had a ROLLBACK operation after the last checkpoint or that was left active (with neither a COMMIT nor a ROLLBACK) before failure , nothing is done because no changes were written to disk
In Write-through technique, the database is immediately updated by transaction operations during the transaction’s execution, even before the transaction reaches its commit point.
If a transaction aborts, a undo operation need to be done.
The recovery process using write-through follows these steps:
- first 3 points same as above.
- For a transaction that had a ROLLBACK operation after the last checkpoint or that was left active (with neither a COMMIT nor a ROLLBACK) before failure, the DBMS undo the transaction using the before values in transaction log.
TRL
ID |
TRX
NUM |
Prev
PTR |
Next
PTR |
Operation
|
Table ID
|
Row
Value |
Attribute
|
Before
|
After Value
|
341
|
101
|
Null
|
352
|
START
|
**Start Transaction
| ||||
352
|
101
|
341
|
363
|
UPDATE
|
PRODUCT
|
P01
|
QOH
|
20
|
18
|
363
|
101
|
352
|
365
|
UPDATE
|
CUSTOMER
|
201
|
baldue
|
100
|
120
|
365
|
101
|
363
|
Null
|
COMMIT
|
**End of transaction
| ||||
397
|
106
|
Null
|
405
|
START
|
**Start Transaction
| ||||
405
|
106
|
397
|
415
|
INSERT
|
INVOICE
|
305
|
305
| ||
415
|
106
|
405
|
419
|
INSERT
|
LINE
|
305,L01
|
305,L01,P05
| ||
419
|
106
|
415
|
427
|
UPDATE
|
PRODUCT
|
P05
|
QOH
|
120
|
119
|
423
|
CHECK POINT
| ||||||||
427
|
106
|
419
|
431
|
UPDATE
|
CUSTOMER
|
202
|
baldue
|
500
|
1050
|
431
|
106
|
427
|
Null
|
COMMIT
|
**End of transaction
| ||||
521
|
155
|
Null
|
525
|
START
|
**Start Transaction
| ||||
525
|
155
|
521
|
528
|
UPDATE
|
PRODUCT
|
P08
|
QOH
|
100
|
80
|
528
|
155
|
525
|
Null
|
COMMIT
|
**End of transaction
| ||||
***C*R*A*S*H***
|
Transaction 101 :
UPDATE product SET qoh=qoh-2 WHERE pno=’P01’;
UPDATE customer SET baldue =baldue+20 WHERE cno=201;
COMMIT;
Transaction 106:
INSERT INTO Invoice VALUES(305,202,SYSDATE());
INSERT INTO line VALUES(305,’L01’,’P05’,1,550);
UPDATE product SET qoh=qoh-1 WHERE pno=’P05’;
UPDATE customer SET baldue =baldue+550 WHERE cno=202;
COMMIT;
Transaction 155:
UPDATE product SET qoh=qoh-20 WHERE pno=’P08’;
COMMIT;
Database recovery process for a DBMS using deferred update method is as follows
- Identify the last checkpoint. In this case it is TRL ID 423. This was the last time database buffers were physically written to disk.
- Transaction 101 committed before the last check point. All changes were already written to disk and so no action to be taken
- For each transaction committed after the last checkpoint, the DBMS does
for example: for transaction 106:
1.Find COMMIT (TRL ID 457)
2.Use the previous pointer values to locate the start of the transaction (TRL ID 397)
3.Use the next pointer values to locate each DML statement and apply the changes to disk, using the
after values (Start with TRL ID 405, then 415,419,427 and 431)
4.Repeat the process for transaction 155 - Transactions that ended with ROLLBACK and that were active at the time of crash, nothing is done because no changes were written to disk
No comments:
Post a Comment