
The below post is notes prepared by me by studying the book "Database Systems Design, Implementation and Management" by Peter Rob and Carlos Coronel
Content, examples and diagrams are taken from that book.
Distributed Database Management Systems
Q: What are the disadvantages of centralized database management system?
- Performance degradation due to growing number of remote locations over greater distances.
- High costs associated with maintaining and operating large central (mainframe) database systems
- Reliability problems created by dependence on a central site(single point of failure syndrome) and the need for data replication.
- Scalability problems associated with the physical limits imposed by a single location(temperature conditioning and power consumption)
- Organizational rigidity imposed by the database might not support the flexibility and agility required by modern global organizations.
Q: What is Distributed database
Ans A distributed database management system ( DDBMS ) governs the storage and processing of logically related data over interconnected computer systems in which both data and processing functions are distributed among several sites.
Q: What is DDBMS
Ans: The software system that permits the management of the distributed database and makes the distribution transparent to users.
Q: What are the advantages and disadvantages of DDBMS
Ans: Advantages
- Data are located near the greatest demand site.
- Faster data access as end users work with only a locally stored subset of the company data.
- Faster data processing as the workload is distributed at several sites.
- Growth facilitation as new sites can be added without affecting other sites
- Improved communication as local sites foster better communication between customer and staff
- Reduced operating costs as development work is done more cheaply and more quickly on low-cost PCs than on mainframes
- User friendly interface as the GUI simplifies training and use for end users
- Less danger of single point failure: when one computer fails, the workload is picked up by other workstations as data are distributed at multiple sites.
- Processor independence : The end user is able to access any available copy of the data, and an end users request is processed by any processor at the data location
Disadvantages
- Complexity of management and control: Applications must recognize data location and they must be able to stitch together data from various sites.
- Technological difficuilty: Data integrity, transaction management, concurrency control, security, back up recovery, query optimization, access path selection etc… must all be addressed and resolved
- Security : The probability of security lapses increases when data are located at multiple sites. The responsibility of data management will be shared by different people at several sites.
- Lack of standards: There are no standard communication protocols at the database level. For example, different database vendors employ different often incompatible techniques to manage the distribution of data and processing in a DDBMS environment.
- Increased storage and infrastructure requirements: multiple copies of data are required at different sites, thus requiring additional disk storage space.
- Increased training cost
- Costs: Distributed databases require duplicated infrastructure to operate (physical location, environment, personnel, software, licensing etc)
Distributed processing system in centralized database
Although the database resides at only one site, each site can access the data and update the database. That is, shares the database processing chores among several sites.
These sites are connected through a communication network. Refer book for diagram
Distributed database requires distributed processing.
|
Distributed processing may be based on centralized database or distributed database
|
Both distributed processing and databases require a network to connect all components
|
Distribution database system
In a distribution database system, a database is composed of several parts known as database fragments.
The database fragments are located at different sites and can be replicated among various sites.
Distributed database requires distributed processing. Refer book for diagram
Each database fragment is managed by local database process. (Distributed processing)
For the management of distributed data to occur, copies or parts of database processing functions must be distributed to all data storage sites.
Characteristics of DDBMS
The DBMS must have the following functions to be classified as distributed:
- Application interface to interact with the end user, application programs and other DBMSs within the DDB.
- Validation to analyze data requests for syntax correctness.
- Transformation to decompose complex requests into atomic data request components
- Query optimization to find the best access strategy
- Mapping to determine the data location of local and remote fragments.
- I/O interface to read or write data from or to permanent local storage.
- Formatting to prepare the data for presentation to the end user or to an application program
- Security to provide data privacy at both local and remote databases.
- Back up and recovery to ensure the availability and recoverability of the database in case of a failure.
- DB administration features for the database administrator
- Concurrency control to manage simultaneous data access and to ensure data consistency across data fragments in the DDBMS.
- Transaction management to ensure that the data moves from one consistent state to another. This activity includes the synchronization of local and remote transactions as well as transactions across multiple distributed segments.
Centralised DBMS functions
- Receiving an application on end user’s request
- Validate, analyse and decompose the request. The request might include mathematical and/or logical operations.
- Ex: SELECT all customers with a balance > $1000.
The request might require data from only a single table or it might require access to several tables. - Map the request’s logical -to -physical data components.
- Decompose the request into several disk I/O operations
- Search for, locate, read and validate the data.
- Ensure database consistency, security and integrity.
- Validate the data for the conditions, if any, specified by the request.
- Present the selected data in the required format
DDBMS components
- Computers workstations (sites or nodes). The DDBMS must be independent of the computer system hardware
- Network hardware and software components that reside in each workstation to allow all sites to interact and exchange data. Because the components-computers, O.S, network hardware etc-- are likely to be supplied by different vendors, it is best to ensure that DDB functions can be run on multiple platforms.
- Communication media that carry the data from one workstation to another.
The DDBMS must be communications media-independent - The transaction processor (TP) also known as application processor(AP) or the transaction manager (TM), which is the software components found in each computer that requests data.The transaction processor receives and processes the application’s data requests (remote and local).
- The data processor (DP) also known as the data manager(DM), which is the software component residing on each computer that stores and retrieves data located at the site.
A DP may even be a centralized DBMS.
The communication between TPs and DPs is possible through protocols used by the DDBMS
The protocol determines how the DDB system will
1.Interface with the network to transfer data and commands between DPs and TPs.
2.Synchronize all data received from DPs(TP side)
3.and route retrieved data to appropriate TPs(DP side)
4. Ensure database functions like security, concurrency control, back up and recovery in DDB
DPs and TPs can be added to the system without affecting the operations of the other components.
DPs and TPs can reside on the same computer.
Levels of data and process distribution
Current database systems can be classified on the basis of how process distribution and data distribution are supported.
For ex: a DBMS may store data at a single site or in multiple sites and
may support data processing at a single site or at multiple sites.

Single-Site Processing, Single-Site Data (SPSD)(Centralized)
- all processing is done on a single host computer
- all data are stored on the host computer’s local disk system.
Ex: mainframe systems, single processor server and multiple processor server systems)
The functions of TP and DP are embedded within the DBMS located on single computer.
The DBMS usually runs under a time sharing, multitasking O.S, which allows several processes to run concurrently on a host computer
Multiple-Site Processing, Single Site Data (MPSD)- multiple processes run on different computers sharing a single data repository
This scenario requires a network file server running applications that are accessed through a network
- The TP on each workstation routes all network data requests to the file server.
- Only the data storage input/output (I/O) is handled by the file server, so offers limited capability of distributed processing.
- The end user must make direct reference to the fileserver to access remote data.
- All record and file locking activities are done at the end-user location
- All data selection, search and update functions take place at the workstation,
thus requiring that entire file travel through the network for processing at the workstation.
Such a requirement increases network traffic, slows response time and increase communication costs.
For ex: File server computer stores a CUSTOMER table containing 10000 data rows, 50 of which have
balances >$1000. Suppose site A issues the query: SELECT * FROM customer WHERE cus_balance>1000;
All 10000 CUSTOMER rows must travel through the network to be evaluated at site A
Client/Server architecture
|
MPSD
|
All database processing is done at server site
|
All database processing is done at client site
|
Thus reduces network traffic
|
Thus increases network traffic
|
Capable of supporting data at multiple sites.
|
Requires database to be located at a single site
|
Processing is distributed
|
Processing is not distributed
|
Performs multiple site processing
|
Multiple-Site Processing, Multiple-Site Data(MPMD) describes a fully DDB with support for multiple data processors and transaction processors at multiple sites
Types of DDBMS:
Depending on the level of support for various types of centralized DBMSs, DDBMSs are classified as
homogenous DDBMS
|
heterogenous DDBMS
|
Integrates only one type of centralized DBMS over a network.
|
Integrates different types of centralized DBMS over a network.
|
The same DBMS will be running on different server platforms (single processor server, multi-processor server)
|
Fully heterogenous DDBMS will support different DBMSs that even support different data models (relational, hierarchical or network) running on different computer systems such as mainframes and PCs
|
Some DDBMS implementations support several platforms, O.S and networks and allow access remote data access to another DBMS, but subject to certain restrictions.
Remote access is provided on a read-only basis and does not support write privileges.
Restrictions are placed on the
- number of remote tables that may be accessed in a single transaction.
- number of distinct databases that may be accessed
- database model that may be accessed. Access may be provided to relational databases but not to network or hierarchical databases.
Transparency features or functional characteristics
Allowing End user to feel like the database’s only user.
User believe that he is working with a centralized DBMS
All complexities are hidden or transparent to the user.
- Distribution transparency: it makes dispersed database look like a single database to the end user.
- Transaction transparency: Allows a transaction to update data at more than one
network site.
Transaction transparency ensures that the transaction will be either entirely completed or aborted, thus maintaining data integrity - Failure transparency ensures that the system will continue to operate in the event of a node failure.
Functions that were lost because of failure will be picked up by another network node - Performance transparency :The system will not suffer any performance degradation
due to its use on a network or due to the network’s platform differences
Ensures that the system will find the most cost-effective path to access remote data. - Heterogeneity transparency :Allows integration of several different local DBMSs (relational, hierarchical and network) under a common or global schema
The DBMS is responsible for translating the data requests from the global schema to the local DBMS schema
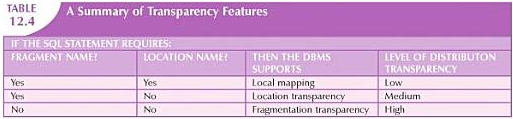
Distribution transparency
Three levels of distribution transparency are
- Fragmentation transparency: is the highest level of transparency.
Neither fragment names nor fragment locations are specified prior to data access. - Location transparency: end user must specify the database fragment names but not their locations
- Location mapping transparency: end user need to specify both the fragment names and their locations
Ex: The CUSTOMER table contains cno,cname,city attributes
The CUSTOMER data are distributed over 3 different locations: NewYork, Atlanta and Miami
The table is divided by location i.e.., NewYork customers data are stored in fragment C1,
Atlanta customers data are stored in fragment C2
Miami customers data are stored in fragment C3
and each fragment is unique i.e.., it indicated each row is unique
No portion of the table is replicated at any other site.
Case 1: The database supports Fragmentation Transparency
SELECT * FROM customer; (no fragment names or location specified)
Case 2: The database supports Location Transparency
SELECT * FROM C1;
UNION
SELECT * FROM C2; (fragment names are specified and locations are not specified)
UNION
SELECT * FROM C3;
Case 3: The database supports Location Mapping Transparency
SELECT * FROM C1 NODE NY;
UNION
SELECT * FROM C2 NODE ATL; (fragment names are specified and locations are not specified)
UNION
SELECT * FROM C3 NODE MIA;
Distribution transparency is supported by distributed data dictionary (DDD) or distributed data catalogue (DDC). The DDC contains distributed global schema i.e.., entire database description. The DDC is itself distributed and replicated. Therefore, it must maintain consistency through updating all sites
Transaction transparency
Remote request/statements: lets a single SQL statement (or request) reference data at only one remote site or D.P
A remote transaction contains one or more remote requests, all of which reference one remote site or D.P
consider a transaction at site A
BEGIN WORK
UPDATE product SET qoh = qoh-1 WHERE pno = ‘P01’;
INSERT INTO invoice (invno,cno,invdate) VALUES (305, 202,SYSDATE);
COMMIT WORK;
Note the following remote transaction features:
- The transaction updates PRODUCT and INVOICE table (located at SiteC)
- The remote transaction is sent to and executed at the remote site C.
- The entire transaction can reference and be executed at only one remote DP
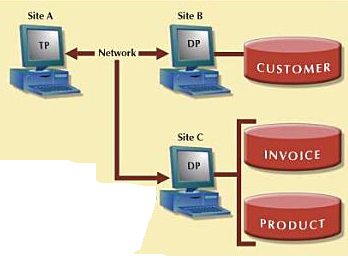
A distributed transaction contains one or more requests and
Each request can access only one remote site at a time i.e..,
It allows a transaction to reference several different local or remote DP sites .
Consider a transaction at site A
BEGIN WORK
UPDATE product SET qoh = qoh-1 WHERE pno = ‘P01’;
INSERT INTO invoice (invno,cno,invdate) VALUES (305, 202,SYSDATE);
UPDATE customer SET baldue = baldue + 10 WHERE cno = 202;
COMMIT WORK;
Note the following following features
- The transaction references two remote sites (B and C)
- The first two requests (UPDATE PRODUCT and INSERT INTO INVOICE) are processed by the DP at remote site C, and the last request is processed by DP at the remote site B.
- Each request can access only one remote site at a time.
The third characteristics may create problems
If suppose the table PRODUCT is divided into PROD1 and PROD2, located at Site B and C respectively, then a distributed transaction cannot execute the request- SELECT * FROM product; because this request cannot access data from more than one remote site. So the DBMS must support a distributed request.
A distributed request lets a one SQL statement reference data located at several different local or remote DP sites.The ability to execute a distributed request provides fully distributed database processing capabilities because of the ability to :
- Partition a database tables into several fragments
- Reference to one or more of those fragments with only one request.
Distributed Concurrency control
Multisite, multiple-process operations are much more likely to create data inconsistencies and deadlocked transactions than are single-site systems
Q: Explain Two Phase Commit Protocol :
Distributed databases make it possible for a transaction to access data at several sites.
A final commit must not be issued until all sites have committed their parts of the transaction.
Each DP maintains its own transaction log.
The two phase commit protocol requires
DO-UNDO-REDO protocol
Write-Ahead Protocol
DO-UNDO-REDO protocol
DO performs the operation and records the before and after values in the transaction log.
UNDO reverses an operation, using the log entries written by the DO portion
REDO redoes an operation.
To ensure that the DO, UNDO, REDO operations can survive a system crash while they were being executed, a write-ahead protocol is used.
The write-ahead protocol forces the log entries to be written to permanent storage before the actual operation takes place.
There are two types of nodes: the coordinator node and subordinates or cohorts.
Coordinator role is assigned to a node that initiates the transaction
The protocol is implemented in two phases
Phase-1 Preparation
The subordinate nodes receive the message, writes the transaction log, using the write-ahead protocol and
Sends an acknowledgement (YES/PREPARED TO COMMIT) or (NO/NOT PREPARED) message to coordinator.
If all nodes are PREPARED TO COMMIT , the transaction goes to phase -2
If one or more nodes reply NO or NOT PREPARED The coordinator broadcasts a ABORT message to all subordinates
Phase -2 The Final Commit
The coordinator broadcasts a COMMIT message to all subordinates and wait for replies
Each subordinate receives the COMMIT message,
and then updates the database using the DO protocol
The subordinates reply with a COMMITTED or NOT COMMITTED message to the coordinator.
If one or more subordinates did not COMMIT, it sends an ABORT message, thereby forcing all subordinates to UNDO
Performance transaparency and query optimization
The DDBMS uses query optimization to decide which copy of the data to access.
The objective of query optimization routine is to minimize the total cost associated with the execution of a request like
1. Access time (I/O) cost involved in accessing the physical data stored on disk
2. Communication cost associated with the transmission of data among nodes in DDB systems
3. CPU time cost associated with the processing overhead of managing distributed transactions
To evaluate query optimization, the TP must receive data from DP, synchronize it, assemble the answer and present it to end user or an application
Most of the algorithms proposed for query optimization are based on two principles:
1. The selection of the optimum execution order.
2. The selection of sites to be accessed to minimize communication costs.
Query optimization algorithms can be evaluated on the basis of operation mode or the timing of its optimization
Operation modes can be classified as manual or automatic--
Cost effective path is found and scheduled by end user or programmer in manual
Cost effective path is found and scheduled by DDBMS.
Classification according to when the optimization is done
1. Static query optimization takes place at compilation time. When the program is submitted to the DBMS for compilation, it creates the plan to access the database.
2. Dynamic query optimization takes place at execution time. Its cost is measured by run- time processing overhead
Classification according to type of information that is used to optimize the query
1. Statistically based query optimization algorithm uses statistical information like size, number of records, average access time of database.
The statistical information is managed by DDBMS and is generated in dynamic mode or in manual mode.
In dynamic statistical generation mode, the DDBMS automatically evaluates and updates the statistics after each access.
2. Rule- based query optimization algorithm is based on a set of user-defined rules to determine the best access strategy. The rules are entered by the end user or database administrator.
Distributed database design
The design of a distribution database design introduces three new issues.
1. How to partition the database into fragments.
2. Which fragment to replicate.
3. Where to locate those fragments and replicas
Data fragmentation :
it allows you to break a single object (database,table etc..) into two or more segments or fragments.
Each fragment can be stored at any site
(Information about data fragmentation is stored in distributed data catalog (DDC), from which it is accessed by TP to process user requests.
Fragmented tables can be recreated from its fragments by using Joins and Unions.)
Horizontal fragmentation:
It refers to the division of a table into subsets (fragments) of rows.
Each fragments is stored at a different node, and
each fragment has unique rows.
(Each fragment represents the equivalent of a SELECT statement, with the WHERE clause on a single attribute.
Ex:
cno
|
cname
|
cstate
|
climit
|
baldue
|
1
|
ANU
|
TN
|
3500
|
2700
|
2
|
RAMA
|
AP
|
6000
|
1200
|
3
|
RADHA
|
TN
|
4000
|
3500
|
4
|
GOPI
|
AP
|
1200
|
550
|
Suppose XYZ company requires information about its customers in the 2 sites (AP, TN)
And each state requires data regarding local customers only
So, distribute data by state ie., define
horizontal fragmentation by state
| |||||
Fragment Name
|
Location
|
Condition
|
Node Name
|
Customer Numbers
|
No. of nodes
|
C1
|
TN
|
cstate = TN
|
CHE
|
1,3
|
2
|
C2
|
AP
|
cstate=AP
|
VJA
|
2,4
|
2
|
Table fragments in 2 states
Table name: C1 location : Tamil Nadu Node:CHE
cno
|
cname
|
cstate
|
climit
|
baldue
|
1
|
ANU
|
TN
|
3500
|
2700
|
3
|
RADHA
|
TN
|
4000
|
3500
|
Table name: C2 location : AndhraPradesh Node:VJA
cno
|
cname
|
cstate
|
climit
|
baldue
|
2
|
RAMA
|
AP
|
6000
|
1200
|
4
|
GOPI
|
AP
|
1200
|
550
|
Vertical fragmentation: It refers to the division of a table into attribute (column) subsets.
Each subset is stored at a different node and
each fragment has unique columns with the exception of the key column which is common to all fragments.
(For Ex: Suppose a company is divided into 2 departments --- service and collection department
Each department is in separate building and has interest in only some of the CUSTOMER attributes.
Vertical fragmentation of CUSTOMER table
| |||
Fragment Name
|
Location
|
Node Name
|
Attribute Names
|
V1
|
Service building
|
SVC
|
cno, cname, cstate
|
V2
|
Collection building
|
ARC
|
cno, climit, baldue
|
Vertically fragmented table contents
Table name: V1 location : Service building Node:SVC
cno
|
cname
|
cstate
|
1
|
ANU
|
TN
|
2
|
RAMA
|
AP
|
3
|
RADHA
|
TN
|
4
|
GOPI
|
AP
|
Table name: V2 location : collection building Node:ARC
cno
|
climit
|
baldue
|
1
|
3500
|
2700
|
2
|
6000
|
1200
|
3
|
4000
|
3500
|
4
|
1200
|
550
|
Mixed fragmentation: It refers to a combination of horizontal vertical strategies.
It requires two step process
- horizontal fragmentation is introduced
- vertical fragmentation is used within each horizontal fragment
(The XYZ company’s structure requires
CUSTOMER data to be fragmented horizontally to 2 company locations (TN,AP) and
Within locations, the data must be fragmented vertically to 2 departments (Service and Collection)
Mixed Fragmentation of CUSTOMER table
Fragment
Name |
Location
|
Horizontal Criteria
|
Node Name
|
Resulting
Rows at Site |
Vertical criteria
attributes at each fragments |
M1
|
TN
|
cstate = TN
|
CHES
|
1,3
|
cno,cname,cstate
|
M2
|
TN
|
cstate = TN
|
CHEC
|
1,3
|
cno,climit,baldue
|
M3
|
AP
|
cstate = AP
|
VJAS
|
2,4
|
cno,cname,cstate
|
M4
|
AP
|
cstate = AP
|
VJAS
|
2,4
|
cno,climit,baldue
|
Table name: M1 location : Tamil Nadu Node:CHES
|
Table name: M2 location : Tamil Nadu
Node:CHEC
| ||||||||||||||||||
Table name: M3 location : AndhraPradesh Node:VJAS
|
Table name: M3 location : AndhraPradesh Node:VJAC
|
Table fragmentation after mixed fragmentation process
Data replication: It refers to the storage of data copies at multiple sites.
Replicated data are subject to the mutual consistency rule , which requires that
1. All copies of data fragments be identical.
2. DDBMS must ensure that a database update is performed at all sites where replicas exist.
Benefits of replication
Fragment copies can be stored at several sites to serve specific information requirements can
- Increases data availability and response time
- Reduced communication and query costs.
- Better load distribution
- Improved data failure tolerance and
Disadvantages
- It imposes additional DDBMS processing overhead because
each copy must be maintained by the system and also have to decide which replicated copy to use. - Increased Transaction time as data must be updated at several sites.
- Storage Cost
Replication Conditions
A fully replicated database stores multiple copies of all database fragments at multiple sites.
A partially replicated database stores multiple copies of some database fragments at multiple sites.
An unreplicated database stores each database fragment at a single site.
Factors for Data Replication Decision
1. Database Size : Replicating large amount of data will have impact on
storage requirements,Data transmission cost and Higher network bandwidth
2. Usage Frequency
How frequently the data need to be updated and how big is the database.
Frequently used data needs to be updated more often.
Data allocation - deciding where to locate data.
Data allocation strategies are as follows:
With the centralized data allocation, the entire database is stored at one site.
With partitioned data allocation, the database is divided into two or more disjoint parts and stored at two or more sites.
With replicated data allocation, copies of one or more database fragments are stored at several sites.
Data allocation algorithms take into consideration a variety of factors:
1. Performance and data availability goals
2. Size, number of rows, the number of relations that an entity maintains with other entities.
3. Types of transactions to be applied to the database, the attributes accessed by each of those transactions.
Explain about Client/Server Architecture
Client/server architecture refers to the way in which computers interact to form a system.
It features a user of resources or a client and a provider of resources or a server .
The architecture can be used to implement a DBMS in which the client is the transaction processor (TP) and the server is the data processor (DP).
Client/Server Architecture
Client/Server Advantages
1. Client/server solutions are less expensive and
allow the end user to use the microcomputer’s graphical user interface (GUI),
thereby improving functionality and simplicity.
allow the end user to use the microcomputer’s graphical user interface (GUI),
thereby improving functionality and simplicity.
2. There are more people with PC skills than with mainframe skills.
3. Numerous data analysis and query tools exist to allow interaction with many of the DBMSs.
4. It is cheap to develop an application for PCs than for mainframes.
Client/Server Disadvantages
1. The client/server architecture creates a more complex environment with different platforms.
2. An increase in the number of users and processing sites often paves the way for security problems.
3. The burden of training increases the cost of maintaining the environment.
No comments:
Post a Comment